Publications
* indicates corresponding author.
-
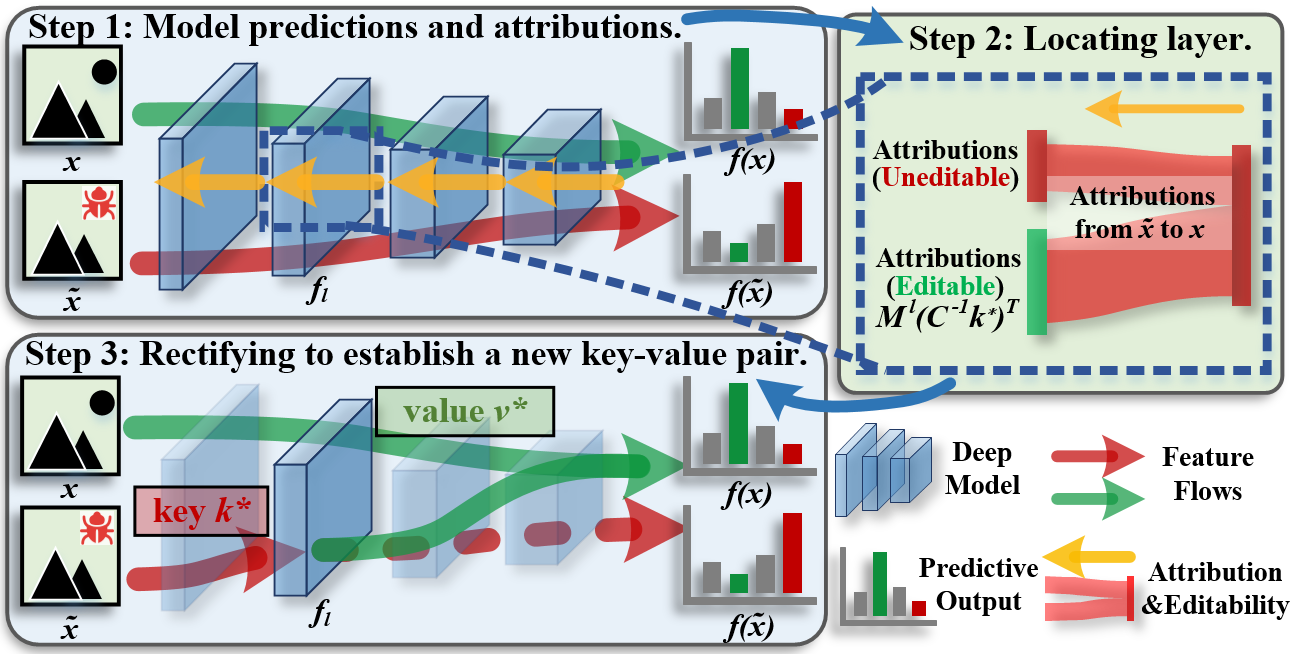 Attribution-Guided Model Rectification of Unreliable Neural Network BehaviorsPeiyu Yang, Naveed Akhtar, Jiantong Jiang*, and Ajmal MianIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
Attribution-Guided Model Rectification of Unreliable Neural Network BehaviorsPeiyu Yang, Naveed Akhtar, Jiantong Jiang*, and Ajmal MianIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026The performance of neural network models deteriorates due to their unreliable behavior on non-robust features of corrupted samples. Owing to their opaque nature, rectifying models to address this problem often necessitates arduous data cleaning and model retraining, resulting in huge computational and manual overhead. In this work, we leverage rank-one model editing to establish an attribution-guided model rectification framework that effectively locates and corrects model unreliable behaviors. We first distinguish our rectification setting from existing model editing, yielding a formulation that corrects unreliable behavior while preserving model performance and reducing reliance on large budgets of cleansed samples. We further reveal a bottleneck of model rectifying arising from heterogeneous editability across layers. To target the primary source of misbehavior, we introduce an attribution-guided layer localization method that quantifies layer-wise editability and identifies the layer most responsible for unreliabilities. Extensive experiments demonstrate the effectiveness of our method in correcting unreliabilities observed for neural Trojans, spurious correlations and feature leakage. Our method shows remarkable performance by achieving its editing objective with as few as a single cleansed sample, which makes it appealing for practice.
@inproceedings{yang2026attribution, title = {Attribution-Guided Model Rectification of Unreliable Neural Network Behaviors}, author = {Yang, Peiyu and Akhtar, Naveed and Jiang, Jiantong and Mian, Ajmal}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2026}, } -
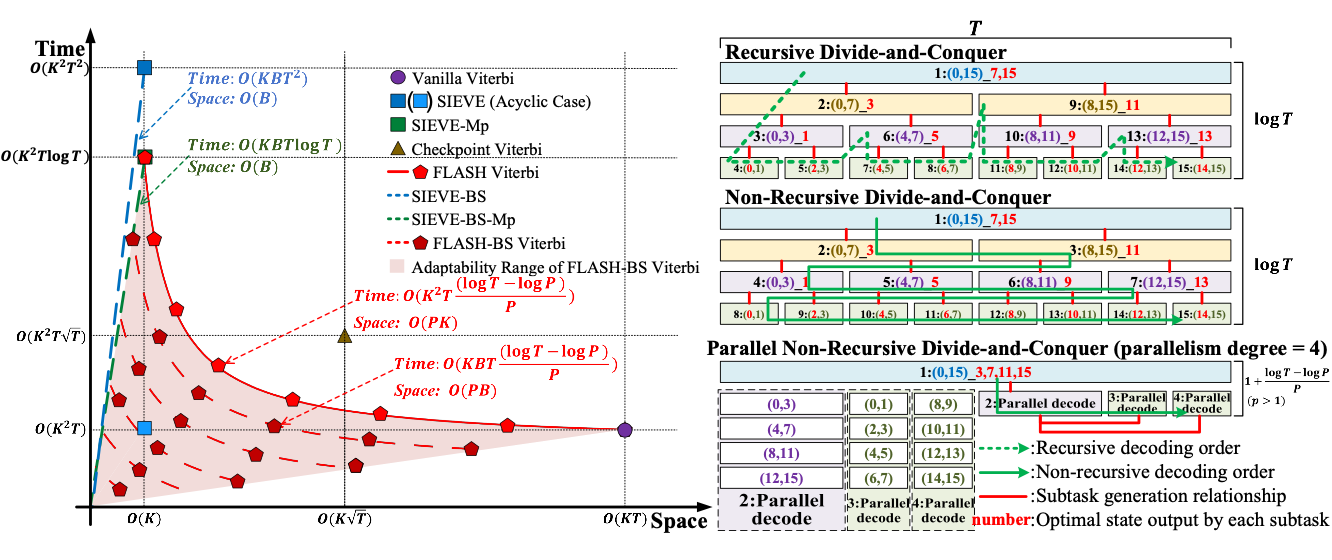 FLASH Viterbi: Fast and Adaptive Viterbi Decoding for Modern Data SystemsZiheng Deng, Xue Liu, Jiantong Jiang, Yankai Li, Qingxu Deng, and Xiaochun YangIEEE International Conference on Data Engineering (ICDE), 2026
FLASH Viterbi: Fast and Adaptive Viterbi Decoding for Modern Data SystemsZiheng Deng, Xue Liu, Jiantong Jiang, Yankai Li, Qingxu Deng, and Xiaochun YangIEEE International Conference on Data Engineering (ICDE), 2026The Viterbi algorithm is a key operator for structured sequence inference in modern data systems, with applications in trajectory analysis, online recommendation, and speech recognition. As these workloads increasingly migrate to resource-constrained edge platforms, standard Viterbi decoding remains memory-intensive and computationally inflexible. Existing methods typically trade decoding time for space efficiency, but often incur significant runtime overhead and lack adaptability to various system constraints. This paper presents FLASH Viterbi, a Fast, Lightweight, Adaptive, and Hardware-Friendly Viterbi decoding operator that enhances adaptability and resource efficiency. FLASH Viterbi combines a non-recursive divide-and-conquer strategy with pruning and parallelization techniques to enhance both time and memory efficiency, making it well-suited for resource-constrained data systems. To further decouple space complexity from the hidden state space size, we present FLASH-BS Viterbi, a dynamic beam search variant built on a memory-efficient data structure. Both proposed algorithms exhibit strong adaptivity to diverse deployment scenarios by dynamically tuning internal parameters. To ensure practical deployment on edge devices, we also develop FPGA-based hardware accelerators for both algorithms, demonstrating high throughput and low resource usage. Extensive experiments show that our algorithms consistently outperform existing baselines in both decoding time and memory efficiency, while preserving adaptability and hardware-friendly characteristics essential for modern data systems. All codes are publicly available at https://github.com/Dzh-16/FLASH-Viterbi.
@inproceedings{deng2026flash, title = {FLASH Viterbi: Fast and Adaptive Viterbi Decoding for Modern Data Systems}, author = {Deng, Ziheng and Liu, Xue and Jiang, Jiantong and Li, Yankai and Deng, Qingxu and Yang, Xiaochun}, booktitle = {IEEE International Conference on Data Engineering (ICDE)}, year = {2026}, }


-
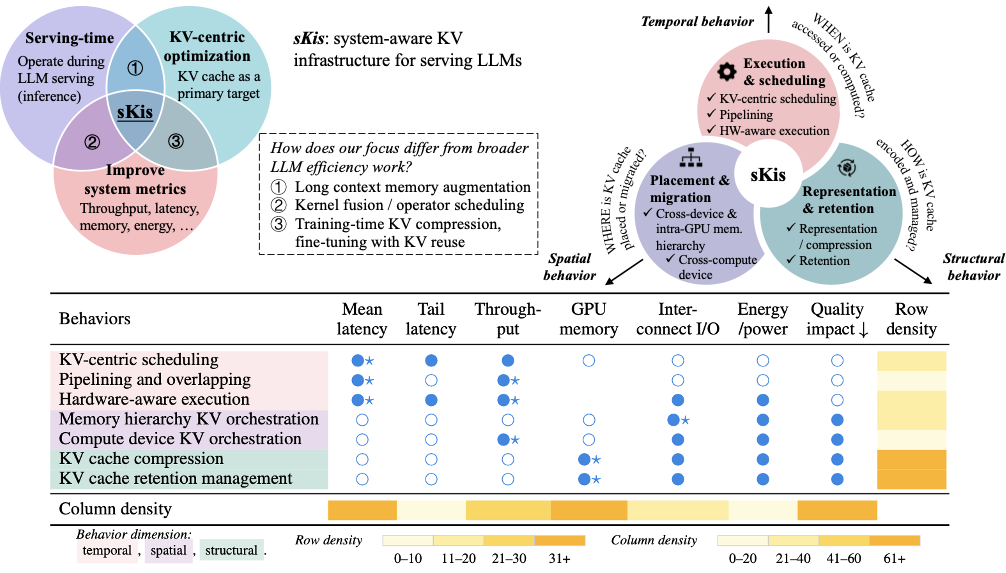 Towards Efficient Large Language Model Serving: A Survey on System-Aware KV Cache OptimizationJiantong Jiang, Peiyu Yang, Rui Zhang, and Feng LiuAuthorea Preprints, 2025
Towards Efficient Large Language Model Serving: A Survey on System-Aware KV Cache OptimizationJiantong Jiang, Peiyu Yang, Rui Zhang, and Feng LiuAuthorea Preprints, 2025Despite the rapid advancements of large language models (LLMs), LLM serving systems remain memory-intensive and costly. The key-value (KV) cache, which stores KV tensors during autoregressive decoding, is crucial for enabling low-latency, high-throughput LLM inference serving. In this survey, we focus on system-aware KV infrastructure for serving LLMs (abbreviated as sKis). We revisit recent work from a system behavior perspective, organizing existing efforts into three dimensions: execution and scheduling (temporal), placement and migration (spatial), and representation and retention (structural). Furthermore, we analyze synergies across behaviors and their links to optimization objectives, highlighting future opportunities. Our work systematizes a rapidly evolving area, providing a foundation for understanding and innovating KV cache designs in modern LLM serving infrastructure.
@article{jiang2025towards, title = {Towards Efficient Large Language Model Serving: A Survey on System-Aware KV Cache Optimization}, author = {Jiang, Jiantong and Yang, Peiyu and Zhang, Rui and Liu, Feng}, journal = {Authorea Preprints}, year = {2025}, publisher = {Authorea}, url = {http://dx.doi.org/10.36227/techrxiv.176046306.66521015/v3}, }

-
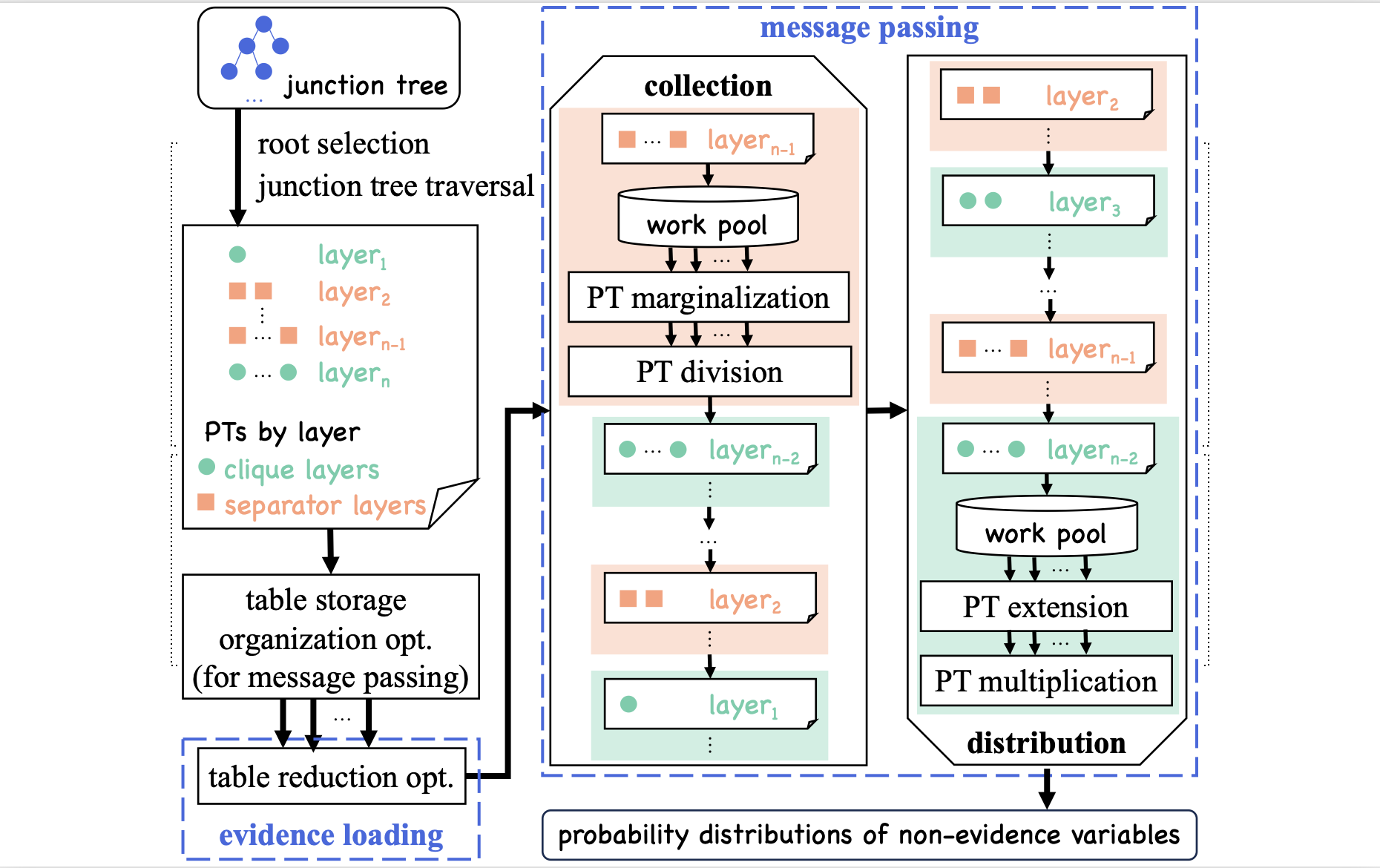 Faster-BNI: Fast Parallel Exact Inference on Bayesian NetworksJiantong Jiang, Zeyi Wen, Atif Mansoor, and Ajmal MianIEEE Transactions on Parallel and Distributed Systems (TPDS), 2024
Faster-BNI: Fast Parallel Exact Inference on Bayesian NetworksJiantong Jiang, Zeyi Wen, Atif Mansoor, and Ajmal MianIEEE Transactions on Parallel and Distributed Systems (TPDS), 2024Bayesian networks (BNs) have recently attracted more attention, because they are interpretable machine learning models and enable a direct representation of causal relations between variables. However, exact inference on BNs is time-consuming, especially for complex problems, which hinders the widespread adoption of BNs. To improve the efficiency, we propose a fast BN exact inference named Faster-BNI on multi-core CPUs. Faster-BNI enhances the efficiency of a well-known BN exact inference algorithm, namely the junction tree algorithm, through hybrid parallelism that tightly integrates coarse- and fine-grained parallelism. Moreover, we identify that the bottleneck of BN exact inference methods lies in recursively updating the potential tables of the network. To reduce the table update cost, Faster-BNI employs novel optimizations, including the reduction of potential tables and re-organizing the potential table storage, to avoid unnecessary memory consumption and simplify potential table operations. Comprehensive experiments on real-world BNs show that the sequential version of Faster-BNI outperforms existing sequential implementation by 9 to 22 times, and the parallel version of Faster-BNI achieves up to 11 times faster inference than its parallel counterparts.
@article{jiang2024faster, title = {Faster-BNI: Fast Parallel Exact Inference on Bayesian Networks}, author = {Jiang, Jiantong and Wen, Zeyi and Mansoor, Atif and Mian, Ajmal}, journal = {IEEE Transactions on Parallel and Distributed Systems (TPDS)}, year = {2024}, volume = {35}, number = {8}, pages = {1444-1455}, publisher = {IEEE}, } -
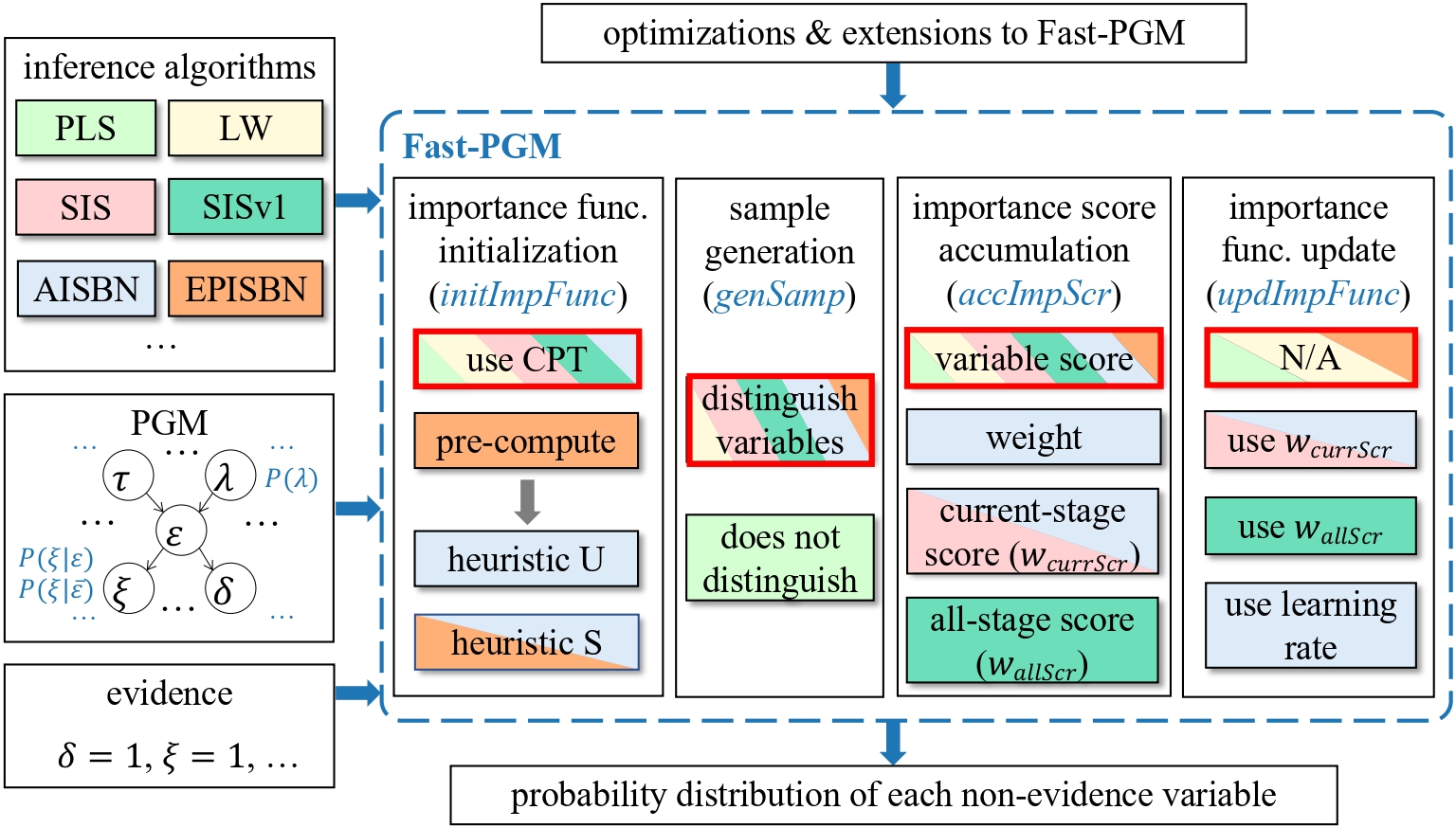 Fast inference for probabilistic graphical modelsJiantong Jiang, Zeyi Wen, Atif Mansoor, and Ajmal MianUSENIX Annual Technical Conference (USENIX ATC), 2024
Fast inference for probabilistic graphical modelsJiantong Jiang, Zeyi Wen, Atif Mansoor, and Ajmal MianUSENIX Annual Technical Conference (USENIX ATC), 2024Probabilistic graphical models (PGMs) have attracted much attention due to their firm theoretical foundation and inherent interpretability. However, existing PGM inference systems are inefficient and lack sufficient generality, due to issues with irregular memory accesses, high computational complexity, and modular design limitation. In this paper, we present Fast-PGM, a fast and parallel PGM inference system for importance sampling-based approximate inference algorithms. Fast-PGM incorporates careful memory management techniques to reduce memory consumption and enhance data locality. It also employs computation and parallelization optimizations to reduce computational complexity and improve the overall efficiency. Furthermore, Fast-PGM offers high generality and flexibility, allowing easy integration with all the mainstream importance sampling-based algorithms. The system abstraction of Fast-PGM facilitates easy optimizations, extensions, and customization for users. Extensive experiments show that Fast-PGM achieves 3 to 20 times speedup over the state-of-the-art implementation. Fast-PGM source code is freely available at https://github.com/jjiantong/FastPGM.
@inproceedings{jiang2024fast, title = {Fast inference for probabilistic graphical models}, author = {Jiang, Jiantong and Wen, Zeyi and Mansoor, Atif and Mian, Ajmal}, booktitle = {USENIX Annual Technical Conference (USENIX ATC)}, pages = {95--110}, year = {2024}, } -
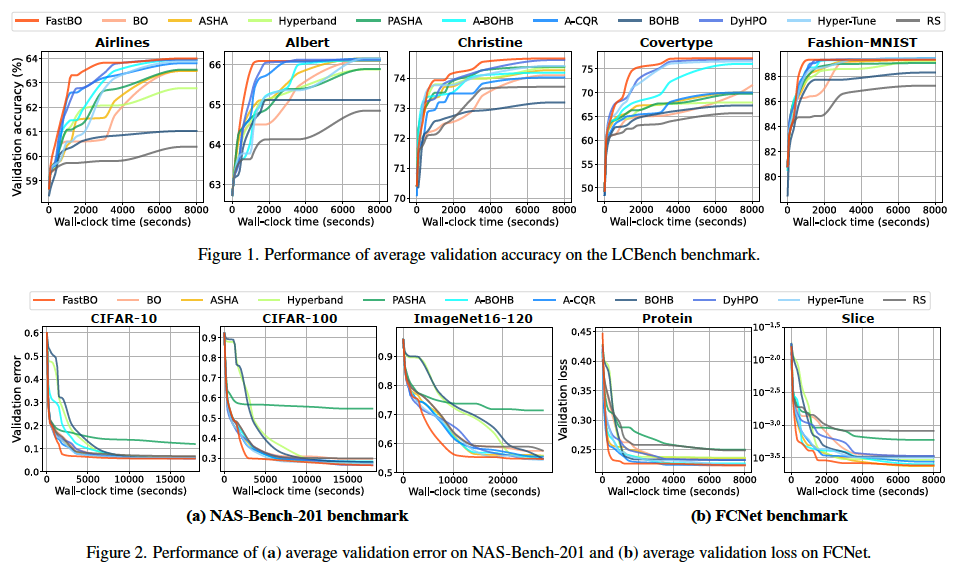 Efficient Hyperparameter Optimization with Adaptive Fidelity IdentificationJiantong Jiang, Zeyi Wen, Atif Mansoor, and Ajmal MianIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Efficient Hyperparameter Optimization with Adaptive Fidelity IdentificationJiantong Jiang, Zeyi Wen, Atif Mansoor, and Ajmal MianIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024Hyperparameter Optimization and Neural Architecture Search are powerful in attaining state-of-the-art machine learning models, with Bayesian Optimization (BO) standing out as a mainstream method. Extending BO into the multi-fidelity setting has been an emerging research topic in this field, but faces the challenge of determining an appropriate fidelity for each hyperparameter configuration to fit the surrogate model. To tackle the challenge, we propose a multi-fidelity BO method named FastBO, which excels in adaptively deciding the fidelity for each configuration and providing strong performance while ensuring efficient resource usage. These advantages are achieved through our proposed techniques based on the concepts of efficient point and saturation point for each configuration, which can be obtained from the empirical learning curve of the configuration, estimated from early observations. Extensive experiments demonstrate FastBO’s superior anytime performance and efficiency in identifying high-quality configurations and architectures. We also show that our method provides a way to extend any single-fidelity method to the multi-fidelity setting, highlighting the wide applicability of our approach.
@inproceedings{jiang2024efficient, title = {Efficient Hyperparameter Optimization with Adaptive Fidelity Identification}, author = {Jiang, Jiantong and Wen, Zeyi and Mansoor, Atif and Mian, Ajmal}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, pages = {26181--26190}, year = {2024}, video = {https://www.bilibili.com/video/BV1CHWDePEb8/?spm_id_from=333.999.0.0} } -
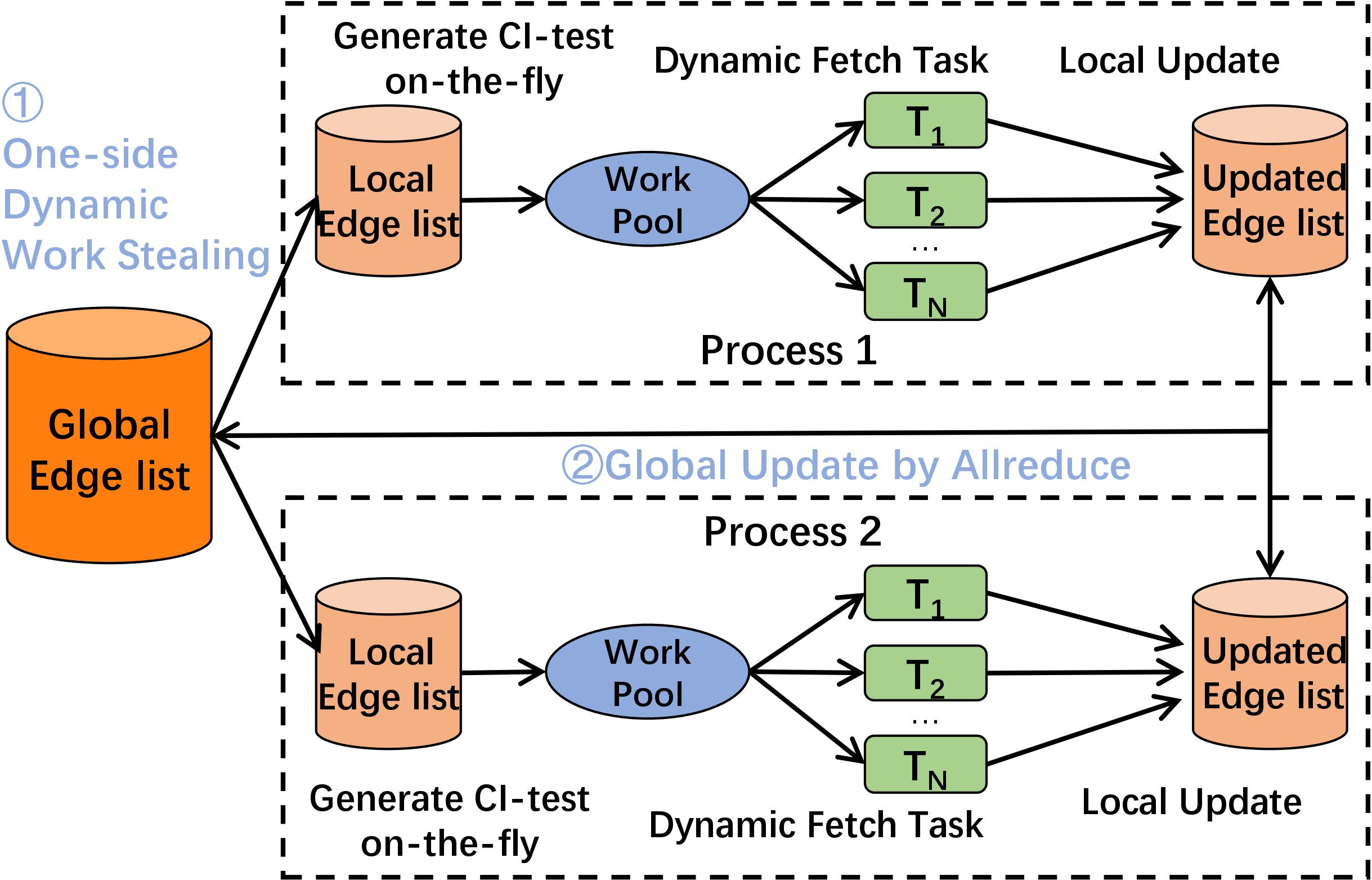 Parallel and Distributed Bayesian Network Structure LearningJian Yang, Jiantong Jiang, Zeyi Wen, and Ajmal MianIEEE Transactions on Parallel and Distributed Systems (TPDS), 2024
Parallel and Distributed Bayesian Network Structure LearningJian Yang, Jiantong Jiang, Zeyi Wen, and Ajmal MianIEEE Transactions on Parallel and Distributed Systems (TPDS), 2024Bayesian networks (BNs) are graphical models representing uncertainty in causal discovery, and have been widely used in medical diagnosis and gene analysis due to their effectiveness and good interpretability. However, mainstream BN structure learning methods are computationally expensive, as they must perform numerous conditional independence (CI) tests to decide the existence of edges. Some researchers attempt to accelerate the learning process by parallelism, but face issues including load unbalancing, costly dominant parallelism overhead. We propose a multi-thread method, namely Fast-BNS version 1 (Fast-BNS-v1 for short), on multi-core CPUs to enhance the efficiency of the BN structure learning. Fast-BNS-v1 incorporates a series of efficiency optimizations, including a dynamic work pool for better scheduling, grouping CI tests to avoid unnecessary operations, a cache-friendly data storage to improve memory efficiency, and on-the-fly conditioning sets generation to avoid extra memory consumption.To further boost learning performance, we develop a two-level parallel method Fast-BNS-v2 by integrating edge-level parallelism with multi-processes and CI-level parallelism with multi-threads. Fast-BNS-v2 is equipped with careful optimizations including dynamic work stealing for load balancing, SIMD edge list deletion for list updating, and effective communication policies for synchronization. Comprehensive experiments show that our Fast-BNS achieves 9 to 235 times speedup over the state-of-the-art multi-threaded method on a single machine. When running on multi-machines, it further reduces the execution time of the single-machine implementation by 80%.
@article{yang2024parallel, title = {Parallel and Distributed Bayesian Network Structure Learning}, author = {Yang, Jian and Jiang, Jiantong and Wen, Zeyi and Mian, Ajmal}, journal = {IEEE Transactions on Parallel and Distributed Systems (TPDS)}, year = {2024}, publisher = {IEEE}, }




-
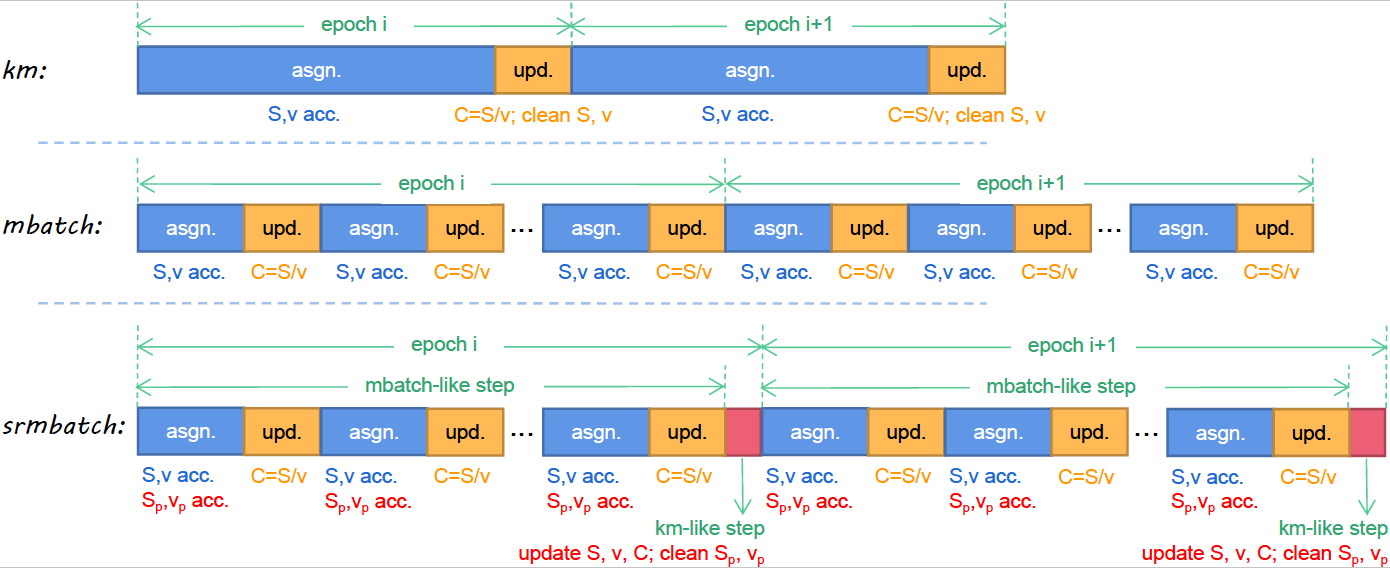 Staleness-reduction Mini-batch K-meansXueying Zhu, Jie Sun, Zhenhao He, Jiantong Jiang, and Zeke WangIEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2023
Staleness-reduction Mini-batch K-meansXueying Zhu, Jie Sun, Zhenhao He, Jiantong Jiang, and Zeke WangIEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2023K-means is a clustering algorithm that has been widely adopted due to its simple implementation and high clustering quality. However, the standard k-means suffers from high computational complexity and is therefore time-consuming. Accordingly, the mini-batch k-means is proposed to significantly reduce computational costs in a manner that updates centroids after performing distance computations on just a mini-batch, rather than a full batch, of samples. Even though the mini-batch k-means converges faster, it leads to a decrease in convergence quality because it introduces staleness during iterations. To this end, in this paper, we propose the staleness-reduction mini-batch k-means (srmbatch), which achieves the best of two worlds: low computational costs like the mini-batch k-means (mbatch) and high clustering quality like the standard k-means (km). Moreover, srmbatch still exposes massive parallelism to be efficiently implemented on multi-core CPUs and many-core GPUs. The experimental results show that srmbatch can converge up to 40X-130X faster than mbatch when reaching the same target loss, and srmbatch is able to reach 0.2%-1.7% lower final loss than that of mbatch.
@article{zhu2023staleness, title = {Staleness-reduction Mini-batch K-means}, author = {Zhu, Xueying and Sun, Jie and He, Zhenhao and Jiang, Jiantong and Wang, Zeke}, journal = {IEEE Transactions on Neural Networks and Learning Systems (TNNLS)}, year = {2023}, publisher = {IEEE}, } -
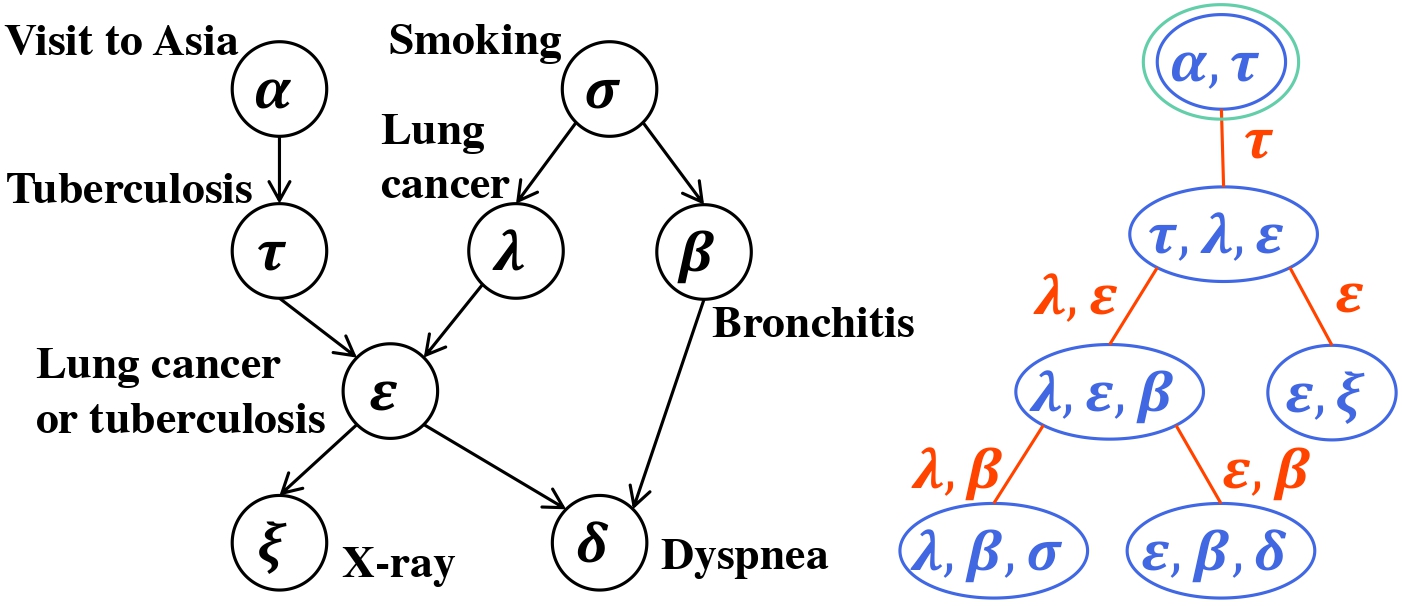 Fast Parallel Exact Inference on Bayesian NetworksJiantong Jiang, Zeyi Wen, Atif Mansoor, and Ajmal MianACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming (PPoPP), 2023
Fast Parallel Exact Inference on Bayesian NetworksJiantong Jiang, Zeyi Wen, Atif Mansoor, and Ajmal MianACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming (PPoPP), 2023Bayesian networks (BNs) are attractive, because they are graphical and interpretable machine learning models. However, exact inference on BNs is time-consuming, especially for complex problems. To improve the efficiency, we propose a fast BN exact inference solution named Fast-BNI on multi-core CPUs. Fast-BNI enhances the efficiency of exact inference through hybrid parallelism that tightly integrates coarse- and fine-grained parallelism. We also propose techniques to further simplify the bottleneck operations of BN exact inference. Fast-BNI source code is freely available at https://github.com/jjiantong/FastBN.
@inproceedings{jiang2023fast, author = {Jiang, Jiantong and Wen, Zeyi and Mansoor, Atif and Mian, Ajmal}, title = {Fast Parallel Exact Inference on Bayesian Networks}, year = {2023}, booktitle = {ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming (PPoPP)}, pages = {425–426}, }


-
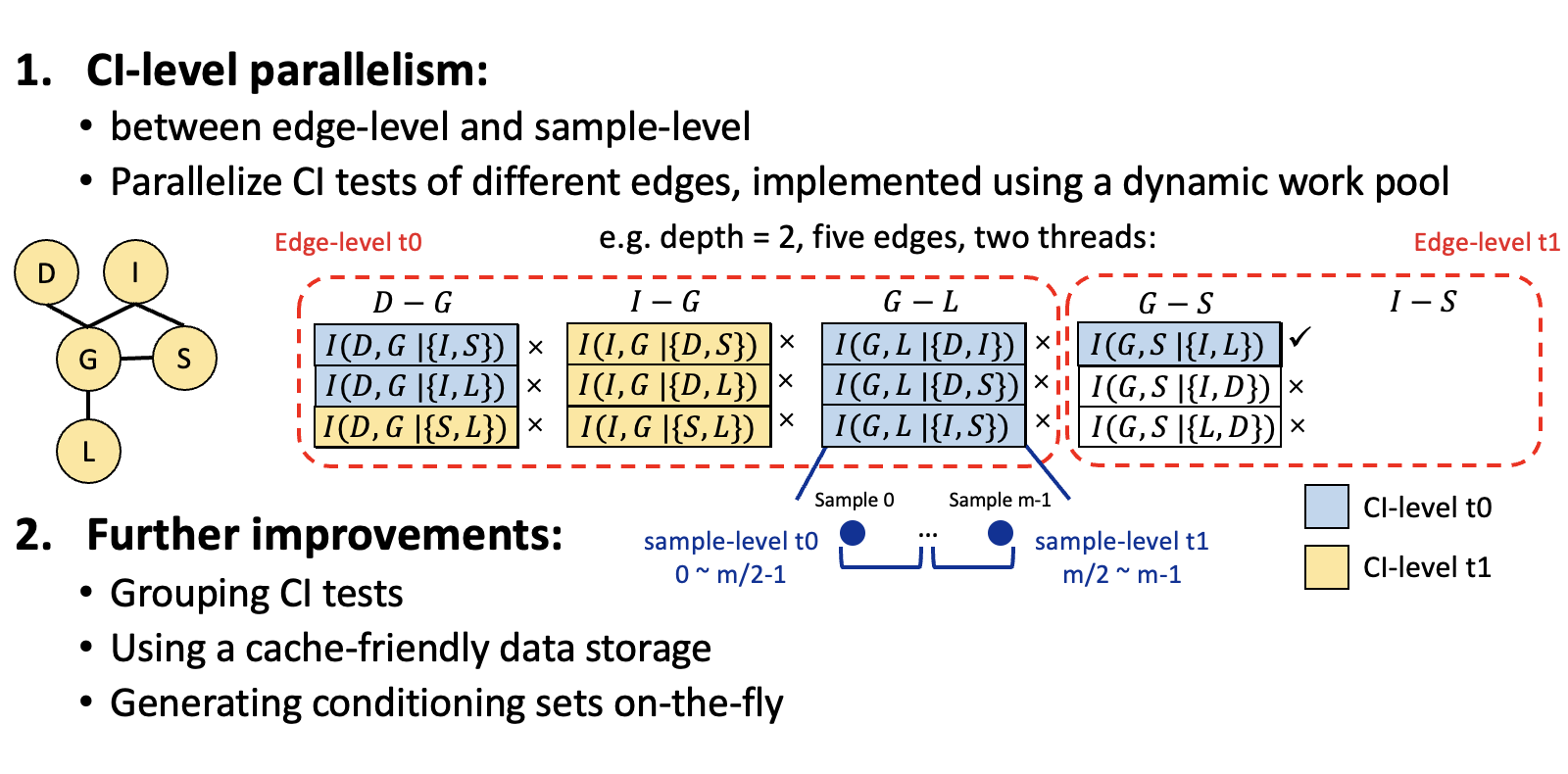 Fast Parallel Bayesian Network Structure LearningJiantong Jiang, Zeyi Wen, and Ajmal MianIEEE International Parallel and Distributed Processing Symposium (IPDPS), 2022
Fast Parallel Bayesian Network Structure LearningJiantong Jiang, Zeyi Wen, and Ajmal MianIEEE International Parallel and Distributed Processing Symposium (IPDPS), 2022Bayesian networks (BNs) are a widely used graphical model in machine learning for representing knowledge with uncertainty. The mainstream BN structure learning methods require performing a large number of conditional independence (CI) tests. The learning process is very time-consuming, especially for high-dimensional problems, which hinders the adoption of BNs to more applications. Existing works attempt to accelerate the learning process with parallelism, but face issues including load unbalancing, costly atomic operations and dominant parallel overhead. In this paper, we propose a fast solution named FastBNS on multi-core CPUs to enhance the efficiency of the BN structure learning. Fast-BNS is powered by a series of efficiency optimizations including (i) designing a dynamic work pool to monitor the processing of edges and to better schedule the workloads among threads, (ii) grouping the CI tests of the edges with the same endpoints to reduce the number of unnecessary CI tests, (iii) using a cache-friendly data storage to improve the memory efficiency, and (iv) generating the conditioning sets onthe-fly to avoid extra memory consumption. A comprehensive experimental study shows that the sequential version of FastBNS is up to 50 times faster than its counterpart, and the parallel version of Fast-BNS achieves 4.8 to 24.5 times speedup over the state-of-the-art multi-threaded solution. Moreover, Fast-BNS has a good scalability to the network size as well as sample size.
@inproceedings{jiang2022fast, author = {Jiang, Jiantong and Wen, Zeyi and Mian, Ajmal}, booktitle = {IEEE International Parallel and Distributed Processing Symposium (IPDPS)}, title = {Fast Parallel Bayesian Network Structure Learning}, year = {2022}, pages = {617-627}, video = {https://www.bilibili.com/video/BV1Ra411R71R/?spm_id_from=333.999.0.0} }

-
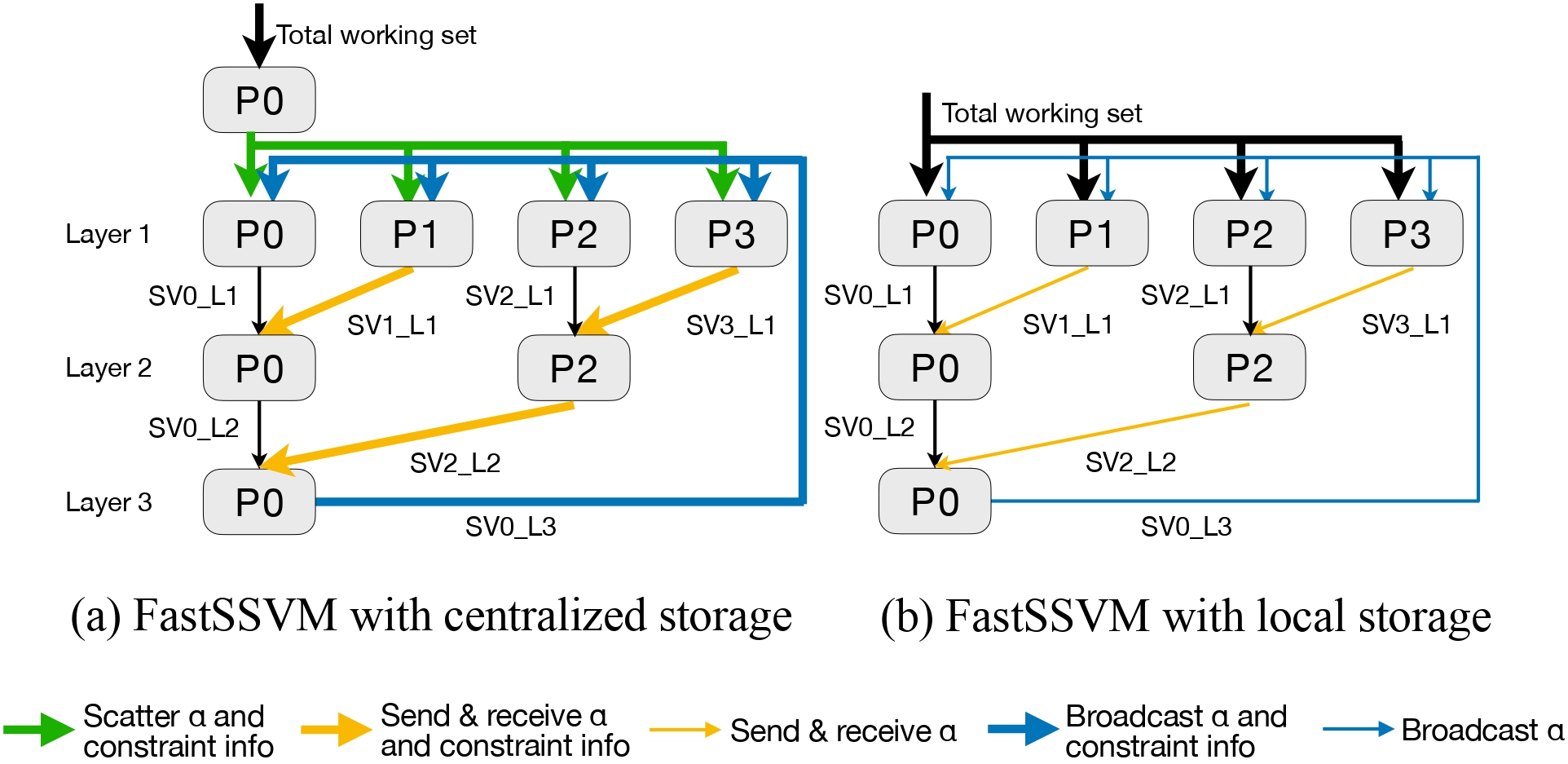 Parallel and distributed structured SVM trainingJiantong Jiang, Zeyi Wen, Zeke Wang, Bingsheng He, and Jian ChenIEEE Transactions on Parallel and Distributed Systems (TPDS), 2021
Parallel and distributed structured SVM trainingJiantong Jiang, Zeyi Wen, Zeke Wang, Bingsheng He, and Jian ChenIEEE Transactions on Parallel and Distributed Systems (TPDS), 2021Structured Support Vector Machines (structured SVMs) are a fundamental machine learning algorithm, and have solid theoretical foundation and high effectiveness in applications such as natural language parsing and computer vision. However, training structured SVMs is very time-consuming, due to the large number of constraints and inferior convergence rates, especially for large training data sets. The high cost of training structured SVMs has hindered its adoption to new applications. In this article, we aim to improve the efficiency of structured SVMs by proposing a parallel and distributed solution (namely FastSSVM) for training structured SVMsbuilding on top of MPI and OpenMP. FastSSVMexploits a series of optimizations (e.g., optimizations on data storage and synchronization) to efficiently use the resources of the nodes in a cluster and the cores of the nodes. Moreover, FastSSVM tackles the large constraint set problem by batch processing and addresses the slow convergence challenge by adapting stop conditions based on the improvement of each iteration. We theoretically prove that our solution is guaranteed to converge to a global optimum. A comprehensive experimental study shows that FastSSVM can achieve at least four times speedup over the existing solutions, and in somecasescan achieve twoto three orders of magnitude speedup.
@article{jiang2021parallel, title = {Parallel and distributed structured SVM training}, author = {Jiang, Jiantong and Wen, Zeyi and Wang, Zeke and He, Bingsheng and Chen, Jian}, journal = {IEEE Transactions on Parallel and Distributed Systems (TPDS)}, volume = {33}, number = {5}, pages = {1084--1096}, year = {2021}, publisher = {IEEE}, }

-
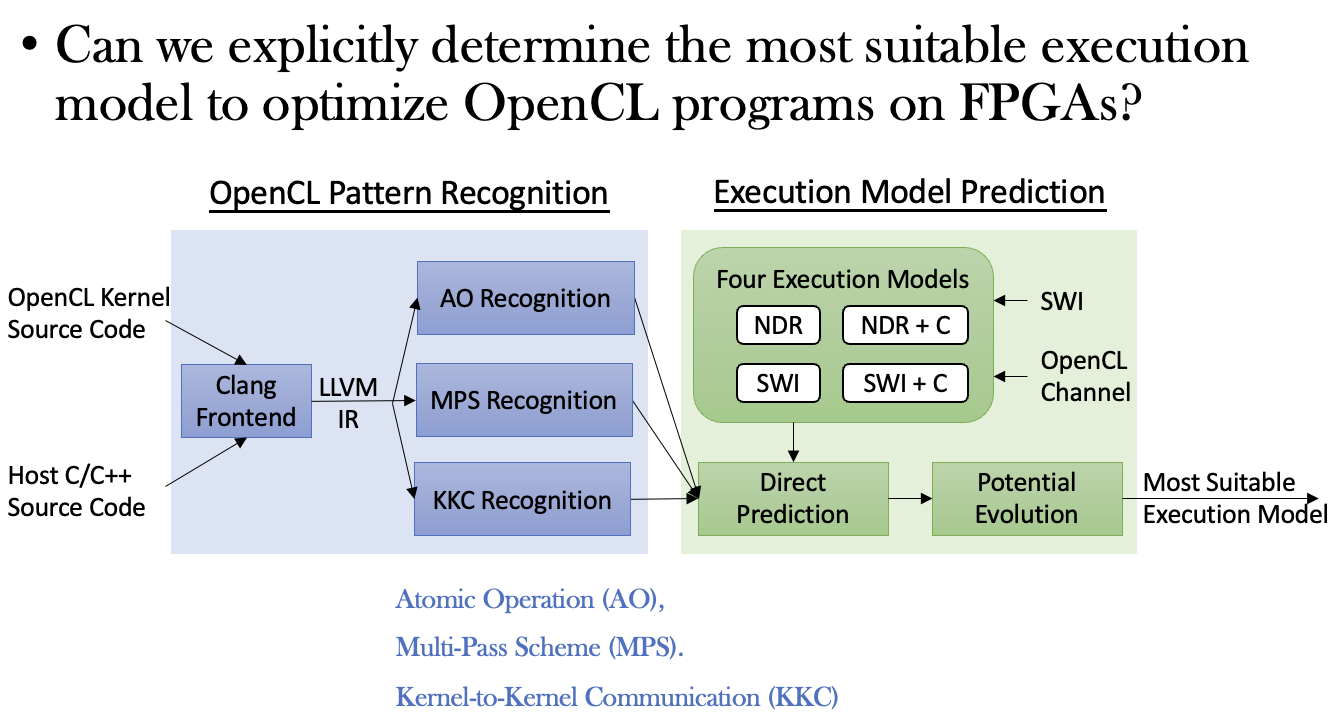 Boyi: A Systematic Framework for Automatically Deciding the Right Execution Model of OpenCL Applications on FPGAsJiantong Jiang, Zeke Wang, Xue Liu, Juan Gómez-Luna, Nan Guan, Qingxu Deng, Wei Zhang, and Onur MutluACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA), 2020
Boyi: A Systematic Framework for Automatically Deciding the Right Execution Model of OpenCL Applications on FPGAsJiantong Jiang, Zeke Wang, Xue Liu, Juan Gómez-Luna, Nan Guan, Qingxu Deng, Wei Zhang, and Onur MutluACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA), 2020FPGA vendors provide OpenCL software development kits for easier programmability, with the goal of replacing the time-consuming and error-prone register-transfer level (RTL) programming. Many studies explore optimization methods (e.g., loop unrolling, local memory) to accelerate OpenCL programs running on FPGAs. These programs typically follow the default OpenCL execution model, where a kernel deploys multiple work-items arranged into work-groups. However, the default execution model is not always a good fit for an application mapped to the FPGA architecture, which is very different from the multithreaded architecture of GPUs, for which OpenCL was originally designed. In this work, we identify three other execution models that can better utilize the FPGA resources for the OpenCL applications that do not fit well into the default execution model. These three execution models are based on two OpenCL features devised for FPGA programming (namely, single work-item kernel and OpenCL channel). We observe that the selection of the right execution model determines the performance upper bound of a particular application, which can vary by two orders magnitude between the most suitable execution model and the most unsuitable one. However, there is no way to select the most suitable execution model other than empiricall exploring the optimization space for the four of them, which can be prohibitive. To help FPGA programmers identify the right execution model, we propose Boyi, a systematic framework that makes automatic decisions by analyzing OpenCL programming patterns in an application. After finding the right execution model with the help of Boyi, programmers can apply other conventional optimizations to reach the performance upper bound. Our experimental evaluation shows that Boyi can 1) accurately determine the right execution model, and 2) greatly reduce the exploration space of conventional optimization methods.
@inproceedings{jiang2020boyi, author = {Jiang, Jiantong and Wang, Zeke and Liu, Xue and G\'{o}mez-Luna, Juan and Guan, Nan and Deng, Qingxu and Zhang, Wei and Mutlu, Onur}, title = {Boyi: A Systematic Framework for Automatically Deciding the Right Execution Model of OpenCL Applications on FPGAs}, year = {2020}, booktitle = {ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA)}, pages = {299–309}, }
